Keywords: HDF5 information set, HDF5 dataset, HDF5 group, HDF5 links, HDF5 datatypes, HDF5 attributes, hyperlabs, MPI-based application, independent mode & collaborative mode
Preface: 学好抽象代数,走遍天下都不怕。
Note: For non-commercial use only.
1. Data model
HDF5 data model defines HDF5 data information set, i.e. a container for annotated associations of array variables, groups, and types. A HDF5 information set is represented by an HDF5 file with a designated root. The elements in a HDF5 dataset include HDF5 datasets, HDF5 groups, and HDF5 data objects.
1.1 HDF5 dataset-Layout strategies and their advantages
HDF5 datasets are array variables whose data elements are logically laid out or shaped as a multidimensional array. The two key properties of the HDF5 dataset includes the rank of the dataset (the number of dimensions), as well as the maximum extant in the respective dimensions (dataspace). With the help of dataspace, the HDF5 dataset can be viewed as as relational variables with the HDF5 dataspace as a system-defined candidate key space.
Remark: the key here is how to understand the structure of multidimensions. Recall the existence of a mapping such that a dataset is linear separable.
Depending on the layout strategy, the maximum extent may be unlimited. Currently, there are three different layout strategy in the HDF5.
a) Contiguous, array elements are laid out as a collection of a linear sequence. The properties of this layout strategy is that we can easily conduct slicing operation on the dataset. However, there is a limit among the maximum extent. (Nearly constant time to get access to any element of the data.)
b) Chunked, Array elements are laid out as a collection of fixed-size regular sub-arrays, or chunks. With the chunked layout strategy, we can extent the dataset to the unlimited size in some or all of the dimensions.
c)_Compacted, the data set smaller than 64KB can be stored in the meta data or can be retrieved from the header (a data type in HDF5).
There is no free lunch in the decision of the layout strategy. HDF5 also provides the users with filter pipelines for the customized and standard raw data. The filter pipelines includes compression and error checking. The chunked layout strategy allows the definition of new filter pipeline. Note that HDF5 do not support filter pipeline for contiguous layout strategy.
Although we can compress the data chunk to gain additional performance improvement, we should be very careful to the determination of the size of the chunk, since it is a trade off between the IO and added pipelines and functionalities.
1.2 HDF5 Groups
An HDF5 group is an explicit representation of an association between zero or more HDF5 information items (includes the HDF5 groups themselves). The association or relationship represented by an HDF5 group is made explicit through a collection of named links to the participating HDF5 information items.
Remark: 在数学里,群是一类特定的代数结构。当然,代数结构本身其实是定义了至少一种运算的非空集合,归根到底还是具备某种性质的集合。运算的本质其实是一种映射,所以群实际上是具备了某些特定类型映射的非空集合。当然,数学上某些具备特殊性质的映射又会产生别的性质,归根到底是在研究映射的性质。这里link的概念实际是从HDF5 information item $\xrightarrow{}$ HDF5 information item的映射。
Link traversal from the HDF5 root group generates the HDF5 information set graph, a rooted, directed, connected graph (是可以有环的).
In one H5 file, there is only one root group. Link traversal from the HDF5 root group generates the HDF5 information set graph, a tooted, directed, multiple edges. Users and applications can refer to the specific information set via the HDF5 pathname.
1.3 HDF5 links
Currently, HDF5 only support unidirectional, single source/destination links only. Further more, the source must be a HDF5 group. The different kinds of HDF5 links can be distinguished by the destination and whether they affect the commitment state of an HDF5 information item.

An HDF5 dataset, group, or datatype object is committed to an HDF5 infoset by linking it to at least one HDF5 group using an HDF5 hard link. (the hard link is determined by the identifiers of the source and the link. Note that there is only one source and one destination in a linked pair).
HDF5 soft and external links are so-called symbolic links because they refer to their destination via an HDF5 pathname or a file name/HDF5 pathname combination. The soft links and external links will not change the commitment of the destination. Note that the destination of the soft and external links may not even exist during the creation of the symbolic links. The destination may cease or even change during the life time of a symbolic links.
1.4 HDF5 Datatypes
The non-scalar HDF5 array variable type has two key ingredients: an HDF5 dataspace which describes its shape, and an HDF5 datatype which describe the type of its data element. Ten families or classes of HDF5 datatypes are currently supported: integer, floating-point, string, bitfield, opaque, compound, reference, enum, variable-length sequence and array.
Note that the compound type is a collection of different datatypes(of course given specific length, 不然对齐毛线).
The reference family includes HDF5 datatype references and HDF5 region references. While the HDF5 data groups can be treated as the explicit representation of a set of HDF5 information items, the reference can be treated as an implicit representation of such association. It is not an association in the HDF5 data model, but it does when it comes to users and applications.
1.5 HDF5 Attributes
HDF5 is used to annotate HDF5 dataset, groups and datatype objects. The name of an HDF5 attribute must be unique in the scope of the HDF5 info item they attached to (kind of key-value pairs).
2. Software architecture

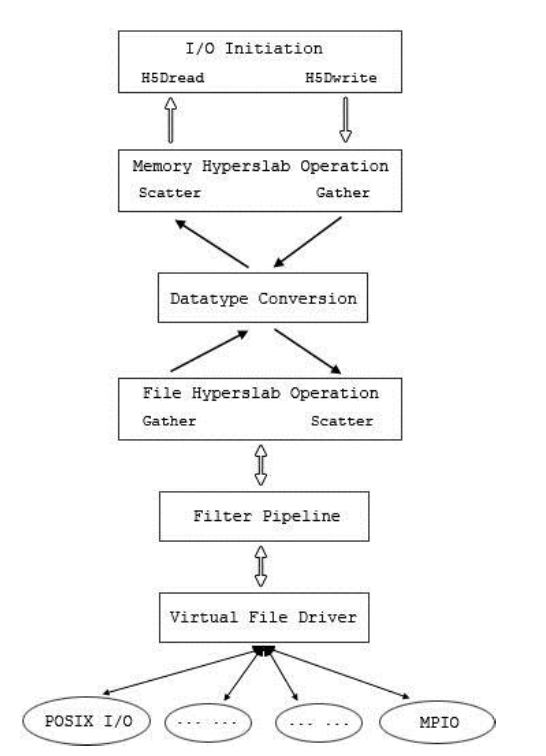
HDF5 hyperslabs are the higher-dimensional analogue of a one-dimensional [start, stride, count, block] pattern. (高维slice)
3. Performance
3.1 Parallel I/O
The HDF5 library can be used for accessing HDF5 files in parallel in MPI-based parallel applications. Parallel access can be independent or collective. The independent mode, the individual MPI process perform IO operation will not be influenced by other MPI process in the same application accessing the same HDF5 file (独立模式下,MPI进程不会被相同应用下的访问相同HDF5文件的进程影响). In collective mode, parallel access is a highly coordinated, cooperative effort involving all MPI processes in an application. 考虑到独立模式下需要考虑各种竞争条件和因此带来的进程交流和同步成本,无非必要,不要上独立模式。
3.2 Indexing
As the introduction in HDF5 dataset, the dataspace attribute can be treated as the system defined key for a relational variable. Simple queries targeting attributes in dataspace-ware attribute (integer lattice coordinates) can take advantage of the quasi-random access or HDF5 region references, and then use traditional indexing techniques to work on the complementary of dataspace-aware attributes. An optimizer (programmer or system component) decides if there is an index (one or more) such that an efficient data access path can be devised.
Comments